Apple said the M5 Max delivers “4x faster LLM prompt processing” than the M4 generation. That’s a big claim. And unlike most Apple marketing numbers, this one actually holds up in certain conditions.
But here’s the thing: “4x faster” doesn’t mean what most people picture. It doesn’t mean you’re chatting with a 120B model at 300 tokens per second. The real story is more interesting and more useful than that, especially if you’re thinking about using the M5 Max as a local AI machine.
This post covers what the community actually measured when the M5 Max landed, how it handles Qwen3.5 models specifically, what Apple’s “4x” claim actually refers to, and whether this machine makes sense for serious local AI work in 2026.
What Apple Actually Claimed (and What It Means)
Let’s start with Apple’s own words, because the framing matters.
Apple advertised “up to 4x faster LLM prompt processing” compared to M4 Pro and M4 Max. The key word is prompt processing, which is the technical term for prefill. This is the phase where the model reads and processes your input before it starts generating a response.
Prefill is compute-bound. It benefits directly from more parallel compute units, which is exactly what the M5’s Neural Accelerators provide. There’s a Neural Accelerator embedded in every single GPU core on the M5 Max. With 40 GPU cores, that’s 40 Neural Accelerators working together during the prefill phase.
Apple’s Claimed vs Community-Tested Numbers
The separate claim, token generation, refers to how fast the model actually types out its response. That’s memory-bandwidth-bound, not compute-bound. The M5 Max’s memory bandwidth is 614 GB/s, up about 12% from the M4 Max’s 546 GB/s. That 12% directly maps to roughly a 15-20% improvement in token generation speed.
Here’s how those two claims break down in practice:
| What Apple Claimed | Improvement Type | What Drives It |
|---|---|---|
| 4x faster prompt processing (prefill) | Compute-bound | Neural Accelerators in every GPU core |
| 15-19% faster token generation | Bandwidth-bound | 614 GB/s memory bandwidth (vs 546 GB/s M4 Max) |
| 4x faster AI image generation | Compute-bound | Same Neural Accelerator architecture |
So the 4x claim is real, it’s just specific to the prefill phase, which is still enormously useful. When you’re working with long documents, large codebases, or extended conversation context, waiting for the model to process your input is often the most annoying bottleneck. The M5 Max genuinely fixes that.
Real Qwen3.5 Benchmark Numbers on M5 Max 128GB
The community moved fast on this. Within days of the M5 Max shipping, r/LocalLLaMA had real benchmark data using Apple’s MLX framework with mlx_lm. These are the numbers that matter.
Qwen3.5-122B-A10B-4bit (MoE Model)
This is the most interesting result. The 122B model has 122 billion total parameters but only activates 10 billion per forward pass, thanks to its Mixture-of-Experts architecture. That’s why it fits comfortably and runs fast.
| Context Length | Prompt Processing Speed | Generation Speed | Peak Memory Used |
|---|---|---|---|
| 4K tokens | 881 tok/s | 65.9 tok/s | 71.9 GB |
| 16K tokens | 1,239 tok/s | 60.6 tok/s | 73.8 GB |
| 32K tokens | 1,067 tok/s | 54.9 tok/s | 76.4 GB |
65 tok/s on a 122B model is genuinely impressive. For reference, a dense 70B model at the same memory footprint would typically land at 15-20 tok/s. The MoE architecture is doing a lot of work here, but the M5 Max is the reason it runs at all on a portable device.
Qwen3-Coder-Next 8-bit
This one was a surprise. Larger on disk than the 122B MoE model due to higher precision, but memory stays below 93GB across all tested context lengths.
| Context Length | Prompt Processing Speed | Generation Speed | Peak Memory Used |
|---|---|---|---|
| 4K tokens | 754 tok/s | 79.3 tok/s | 87.1 GB |
| 16K tokens | 1,802 tok/s | 74.3 tok/s | 88.2 GB |
| 32K tokens | 1,887 tok/s | 68.6 tok/s | 89.7 GB |
| 64K tokens | 1,432 tok/s | 48.2 tok/s | 92.6 GB |
79 tok/s generation and almost 1,900 tok/s prefill at 32K context. For coding workflows where you’re feeding in large files, that prefill number means you’re waiting seconds, not a minute.
Qwen3.5-27B Dense 6-bit
This is where expectations need adjusting. Dense models don’t benefit from MoE’s active-parameter efficiency. At 27B with 6-bit quantization, the model is pulling all parameters on every forward pass.
| Context Length | Prompt Processing Speed | Generation Speed | Peak Memory Used |
|---|---|---|---|
| 4K tokens | 811 tok/s | 23.6 tok/s | 25.3 GB |
| 16K tokens | 686 tok/s | 20.3 tok/s | 27.3 GB |
| 32K tokens | 591 tok/s | 14.9 tok/s | 30.0 GB |
| 64K tokens | 475 tok/s | 14.2 tok/s | 35.4 GB |
23 tok/s on the 27B dense is where some people in the community felt let down. Apple’s “4x” claim being pegged to MoE workloads means dense models see the bandwidth improvement but not the full compute boost. For interactive chat it’s still usable, but not the experience you get with the 122B MoE.
GPT-OSS-120B Q8 (for reference)
The community also ran GPT-OSS-120B in Q8 quantization. This gives a useful data point because it’s a very different architecture than Qwen.
| Context Length | Prompt Processing Speed | Generation Speed | Peak Memory Used |
|---|---|---|---|
| 4K tokens | 1,325 tok/s | 87.9 tok/s | 64.4 GB |
| 16K tokens | 2,710 tok/s | 76.0 tok/s | 64.9 GB |
| 32K tokens | 2,537 tok/s | 64.5 tok/s | 65.5 GB |
87.9 tok/s on a 120B model on a laptop. That’s the headline number for the M5 Max, and it’s what Apple’s marketing is built around, even if they don’t say it quite that directly.
How Does This Compare to the Previous Generation?
M5 Max vs M4 Max (Same Models, Honest Gap)
| Metric | M4 Max | M5 Max | Improvement |
|---|---|---|---|
| Memory Bandwidth | 546 GB/s | 614 GB/s | +12% |
| Token Generation (122B MoE) | ~57 tok/s | ~65 tok/s | ~15% |
| Prompt Processing (prefill, long ctx) | Baseline | Up to 4x faster | Driven by Neural Accelerators |
| Max Unified Memory | 128 GB | 128 GB | No change |
| GPU Cores | 40 | 40 | No change |
The honest answer is that if you’re already on M4 Max and running local AI workloads, the token generation improvement is real but modest, around 15%. The prefill improvement is where you’ll feel the most difference day to day, especially with long context.
M5 Max vs M3 Max
If you’re on M3 Max or earlier, the gap is more meaningful. The Neural Accelerators didn’t exist before M5, which means the entire prefill architecture is new. You’ll feel the jump more.
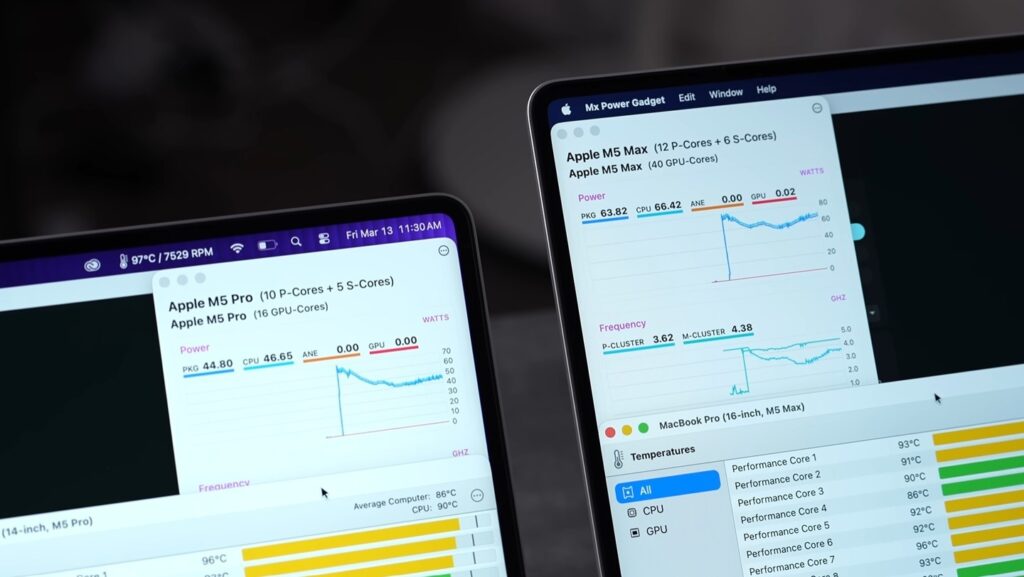
Is the M5 Max Actually Good for Local AI? The Honest Take
Here’s the thing: the M5 Max is arguably the best portable machine for local AI in 2026, but the word portable is doing a lot of work in that sentence.
What It Does Well
MoE models are where this machine genuinely shines. Qwen3.5-122B at 65 tok/s, Qwen3-Coder-Next at nearly 80 tok/s, running entirely on battery, silently, in a 14-inch laptop. There’s nothing else on the market that does this in the same form factor at any price.
The prefill speed improvement is real and immediately noticeable if you work with long contexts. Feeding in a large codebase, a research paper, or a multi-turn conversation with a lot of history no longer involves watching a progress bar for 30 seconds.
Memory capacity also matters here. The 128GB configuration can load models up to around 125B parameters comfortably, and MoE models up to 397B (with quantization). That’s a different category of local AI capability compared to anything with discrete GPU memory.

What the RTX Pro 6000 Does Better
This is worth being honest about. An RTX Pro 6000 with 96GB VRAM runs the same Qwen3.5-122B model at around 93 tok/s, versus the M5 Max’s 65 tok/s. GPU wins on raw generation speed. Prompt processing is also 2-3x faster on Nvidia hardware.
But the RTX Pro 6000 GPU alone costs more than the entire M5 Max MacBook Pro, requires a desktop, runs hot and loud, and has no battery. For a portable machine you actually want to carry and use all day, the comparison doesn’t make sense. For a fixed local AI server where you never move the machine, a GPU build probably still wins on pure throughput.
Dense Models: Lower Your Expectations
Dense models above 30B on the M5 Max are where expectations need calibrating. The 27B dense at 23 tok/s is usable for interactive chat but won’t feel fast. A 70B Q4 dense is in the 18-25 tok/s range. These are slower than what the MoE numbers suggest and slower than the marketing implies.
The practical advice from the community: prefer MoE models on Apple Silicon. Qwen3.5’s MoE architecture was practically designed for this hardware. The 122B-A10B and 35B-A3B variants give you frontier-class capability with active parameter counts that the M5 Max’s bandwidth can actually feed at useful speeds.
Which Qwen3.5 Model Should You Run on M5 Max?
This is the question most people actually want answered.
| Use Case | Recommended Model | Why |
|---|---|---|
| General assistant, chat, writing | Qwen3.5-35B-A3B (4-bit MoE) | Fast, fits in ~20GB, excellent quality |
| Coding and development | Qwen3-Coder-Next 8-bit | Best coding accuracy, still fits in 128GB |
| Long-context document work | Qwen3.5-122B-A10B (4-bit MoE) | Best reasoning at long context, 65 tok/s |
| Fast local responses, agentic tasks | Qwen3.5-9B (4-bit) | Small, 25-30 tok/s on M5 Max, very low memory |
| Vision and multimodal tasks | Qwen3.5-VL variants | Best open-weight vision model available |
The 9B model deserves more attention than it gets. On benchmarks like GPQA Diamond it outperforms GPT-OSS-120B at 13x its size. If you want something that responds quickly and fits in a small memory footprint for agentic workflows, Qwen3.5-9B is a smart choice.
For most serious local AI work, the 122B MoE is the sweet spot on M5 Max. It’s fast enough to feel interactive, smart enough to replace most cloud API use cases, and the memory footprint stays below 80GB so you still have room for other apps.
Should You Buy an M5 Max for Local AI?
It depends on what you’re actually doing and what you already own.
If you’re on M1 or M2 and you run local models: yes, this is a meaningful upgrade. The prefill architecture alone changes the experience with long-context work.
If you’re on M3 Max: the upgrade is real but not urgent unless prefill speed is a daily bottleneck for you.
If you’re on M4 Max: the generation speed improvement is around 15%. Worth knowing about, not worth paying for unless you have other reasons to upgrade.
If you’re building a fixed local AI server and portability doesn’t matter: a high-end GPU workstation still wins on raw throughput. The M5 Max is a portable machine that also happens to be the best portable machine for local AI. Don’t compare it to a desktop workstation and expect it to win.
One more thing to keep in mind: a Mac Studio M5 Ultra is likely coming at WWDC June 2026, potentially with higher memory bandwidth and 192-512GB of unified memory. If you’re not buying for portability, waiting for the Ultra might be the better play for pure local AI performance.
You can dig into more of our MacBook performance benchmark tests to see how these numbers compare across the wider lineup, and if you’re thinking about setting up a full local AI productivity workflow, the model choices above are a good starting point.
The M5 Max is not a perfect machine for every AI workload. But for running large open-weight models locally, privately, and portably in 2026, nothing else comes close at this price.
Quick Reference: M5 Max Local AI Summary
| Spec | M5 Max (128GB) |
|---|---|
| Memory Bandwidth | 614 GB/s |
| Unified Memory | Up to 128 GB |
| GPU Cores | 40 (with Neural Accelerator in each) |
| Max Model Size (comfortable) | ~125B parameters |
| Best Qwen3.5 Model for Speed | Qwen3.5-122B-A10B 4-bit MoE |
| Peak Generation Speed (MoE) | 65-88 tok/s |
| Peak Prompt Processing | Up to 2,710 tok/s |
| Prefill Improvement vs M4 Max | Up to 4x |
| Generation Improvement vs M4 Max | ~15% |
| Starting Price (128GB config) | ~$5,100 |
If you’re already running Ollama or LM Studio and want to know which framework to use: MLX is 20-30% faster than llama.cpp and up to 50% faster than Ollama on Apple Silicon. LM Studio now offers MLX backend support and is the easiest way to get started without touching the terminal. For more on fixing common Mac performance issues that can affect inference speeds, check out our Mac optimization guides.
The community consensus from r/LocalLLaMA is what I’d stand behind: the M5 Max is a real machine for real local AI work. Just run MoE models, use MLX, and don’t expect it to behave like a GPU cluster.